なんでPythonでCloudflareD1とKVを操作?
自主製作のwebサイトでCloudflareを使っているのですが、データベースを操作する必要があって、Typescript+Honoを検討していました
ですが、Honoでバックエンドを作ろうとしたときに、
- wranglerとは?
- Pythonみたいにその場で実行してデバッグしやすい?
- Honoをすぐに使いこなせる?
となったので、Goole Colab上でPythonを書いてデバッグして、raspiサーバーで運用するのが一番短時間で運用まで持っていけると考えて、PythonでCloudflare D1とKVを操作する方法を調べて実装しました
※私がそもそもweb系の仕事をしておらず、ロボットの制御などをする中でPythonやraspiの扱いに慣れていたというのが一番大きな要因です
今回の環境とサンプルプログラムについて
今回のプログラムはGoogle Colab上で実行する前提です
Google Colabで実行出来たら、Pythonが実行できる環境であれば基本的に使えるはずです
また、サンプルのプログラムは下記のGoogle Colabに記載しています
解説とプログラムを読み比べて適宜実行すればわかりやすいと思います

cloudflare-pythonについて
公式でPythonをサポートしているのでこれを使用します
下記コマンドでインストールできます
pip install cloudflareまた、投稿当時のCloudflareのバージョンは3.1.0です
動かない場合はpip install時にバージョン指定をしてください
※3.0.1で以前動かして時があるのですが、3.0.1で動いていたコードが3.1.0で動かないことがあったので、動かないときはバージョンをよくチェックした方がいいと思います
基本的な設定
公式のページの「Usage」あるように最初にクライアントを設定する必要があります
import os
from cloudflare import Cloudflare
from google.colab import userdata
client = Cloudflare(
# This is the default and can be omitted
api_email=userdata.get("CLOUDFLARE_EMAIL"),
# This is the default and can be omitted
api_key=userdata.get("CLOUDFLARE_API_KEY"),
)この時に必要なのは以下の二つです
- CLOUDFLARE_EMAIL
- CLOUDFLARE_API_KEY
- CLOUDFLARE_ACCOUNT_ID
これをGoogle colabのシークレットキーに入れます
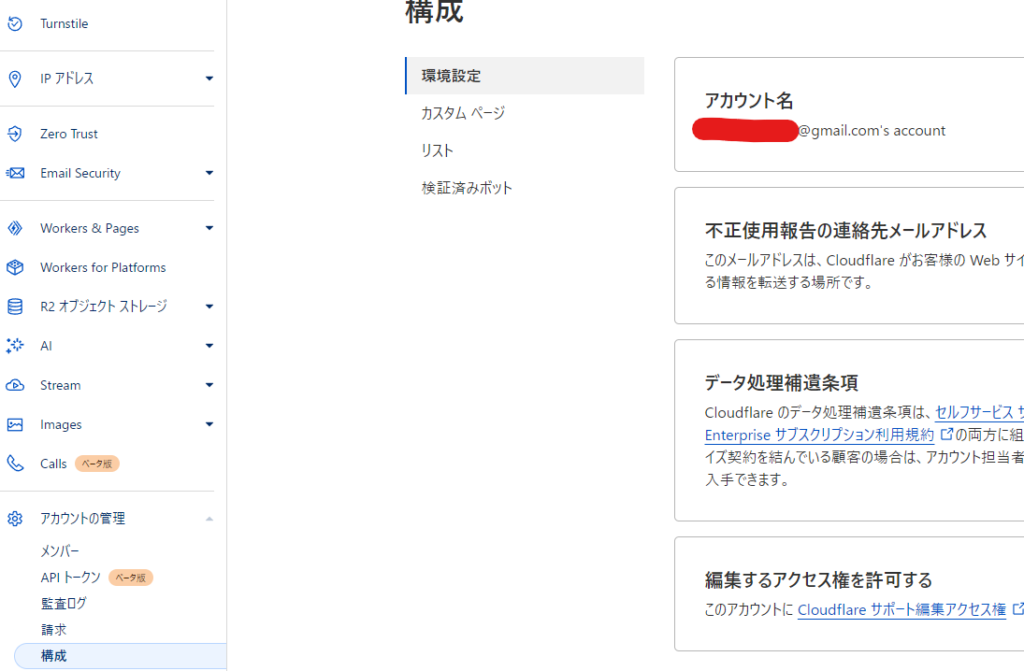
CLOUDFLARE_EMAILの場所
「アカウント名」の下にあるメルアドがCLOUDFLARE_EMAILの環境変数に入れる値になります
「CLOUDFLARE_EMAIL」という名前でGoogle Colabのシークレットに登録します
CLOUDFLARE_API_KEYの場所
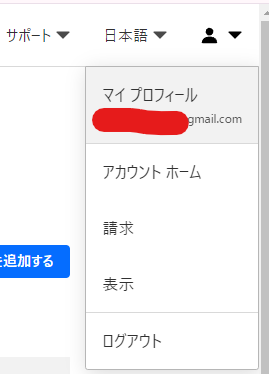
Cloudflareのページの右上の「マイプロフィール」をクリック
左のサイドバーの「APIトークン」をクリック
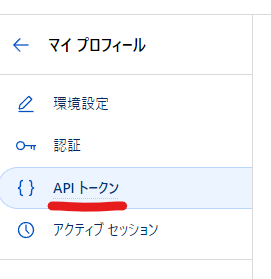
APIキーのGlobal API Keyの表示をクリックするとAPIキーが表示されるのでこれを使用します
「CLOUDFLARE_API_KEY」という名前でGoogle Colabのシークレットに登録します
※このAPIキーはすべてのリソースにアクセスできるAPIキーで本来であれば適切な権限を設定したAPIキーを使用する必要がありますが、個人使用でかつD1とKVをまとめて操作したかったのでGlobal API Keyを使用します

CLOUDFLARE_ACCOUNT_IDの場所
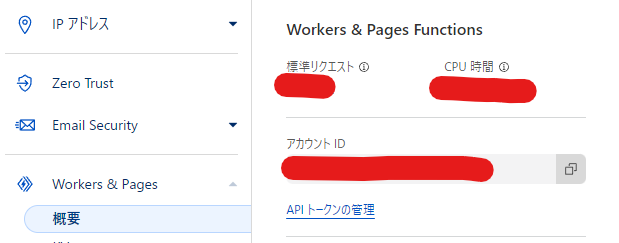
「アカウントID」をコピーして「CLOUDFLARE_ACCOUNT_ID」という名前でGoogle Colabのシークレットに登録します
Cloudflare D1をPythonで操作
Cloudflare D1を操作するにあたって事前にデータベースを作成する必要があります
「D1 SQL データベース」をクリックして、名前を記入してデータベースを作成します
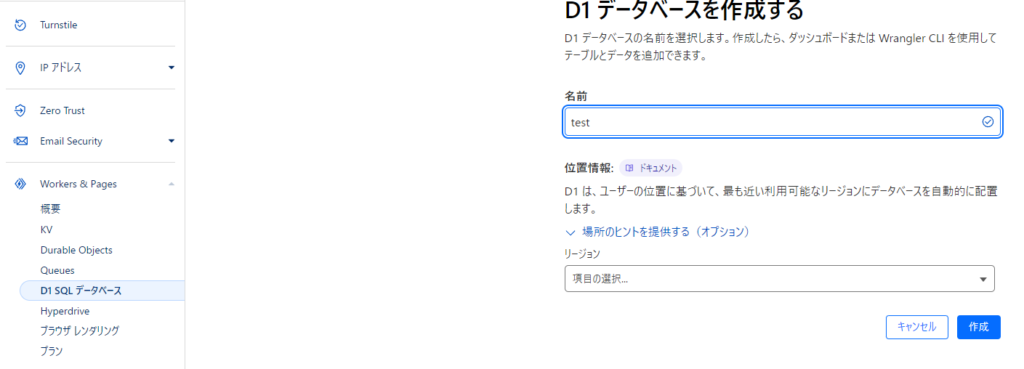
作成後に「データベースID」をコピーして「CLOUDFLARE_DB」という名前でGoogle Colabのシークレットに登録します
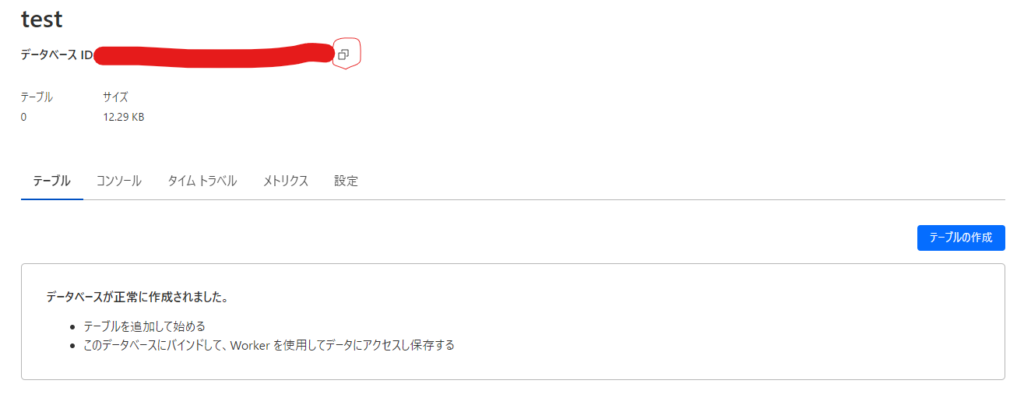
Cloudflare D1のテーブルを作成
今回は例としてフルーツの名前と値段を入れるテーブルを作成します
最初に作成したクライアントに、データベースのIDとアカウントID、最後にクエリを入れて実行するとテーブルが作成できます
create_table_queries = (
"""
CREATE TABLE fruit (
"name" VARCHAR(255),
"price" integer
)
"""
)
client.d1.database.query(database_id=userdata.get("CLOUDFLARE_DB"), account_id=userdata.get("CLOUDFLARE_ACCOUNT_ID"),
sql=create_table_queries)結果は以下のようになるはずです
[QueryResult(meta=Meta(changed_db=True, changes=0.0, duration=0.4131, last_row_id=0.0, rows_read=1.0, rows_written=2.0, size_after=16384.0, served_by='v3-prod'), results=[], success=True)]実行したときの時間(duration)や読み込んだ行数(rows_read)などが分かります
※読み書きする行数はD1の制限対象なので、書き込みや読み込みなどを行うときに確認しておいた方が、無料プランで収まるかなどを判断できるのでこの結果はよく確認した方がいいです
また、Cloudfare D1を確認するとテーブルが作成されていることが分かります
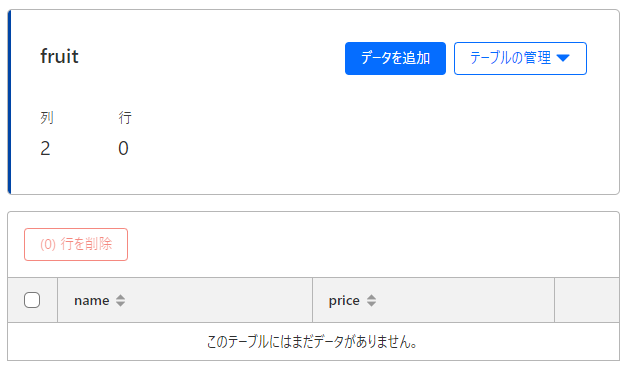
Cloudfare D1のテーブルにデータを書き込み
次にD1にデータを入れていきます
「名前:apple、値段:100」のデータを入れます
regster_queries = (
"""
INSERT INTO fruit (name, price) VALUES ('apple', 100)
"""
)
client.d1.database.query(database_id=userdata.get("CLOUDFLARE_DB"), account_id=userdata.get("CLOUDFLARE_ACCOUNT_ID"),
sql=regster_queries)ここで返ってくる結果を見ると「rows_written=1.0」=1行書き込まれていることが分かります
[QueryResult(meta=Meta(changed_db=True, changes=1.0, duration=0.2292, last_row_id=1.0, rows_read=0.0, rows_written=1.0, size_after=16384.0, served_by='v3-prod'), results=[], success=True)]また、Cloudflareのページを見るとデータが書き込まれていることが分かります
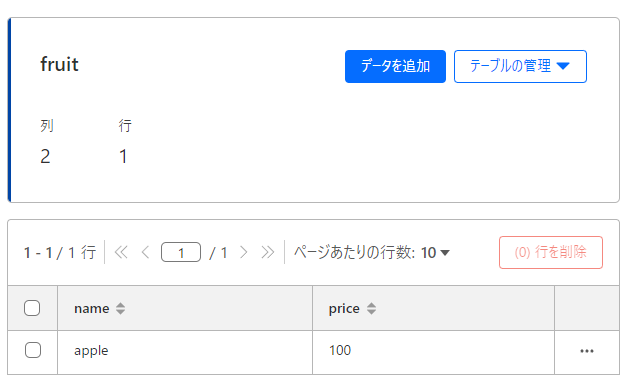
Cloudfalre D1からテーブルのデータの読み込み
先ほど書き込んだデータを読み込んでみます
regster_queries = (
"""
SELECT * FROM fruit
"""
)
res = client.d1.database.query(database_id=userdata.get("CLOUDFLARE_DB"), account_id=userdata.get("CLOUDFLARE_ACCOUNT_ID"),
sql=regster_queries)
print(res[0].results)ここでprintで出力された結果を見ると以下のようになっているはずです
先ほど書き込んだりんごが100円という情報が取得出来ていると思います
[{'name': 'apple', 'price': 100}]補足事項
今回の実装は下記のページのapi.mdを読んで実装したものになります
自分はqueryメソッドでテーブルのデータ読み書きを実行しているものになります
api.mdを見ると他にもメソッドがあるのでテーブルの一覧を取得できるとかできそうですけど、自分には必要なかったので試していません
ただ、引数としてはdatabase_id, account_idが必要なので、先ほど設定したシークレットキーで引数としては足りるはずです
まとめ
PythonでCloudflare D1のテーブル作成からデータの書き込み、データの読み込みを説明しました
少し長くなったのでKVは別のページで解説します

コメント